(*The polls were each taken the day before the election by different organizations, and the election results were used as the standard reference.)
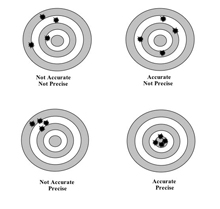
By analogy, accuracy is a statement of how far the shot is from the bull's eye. Precision is a statement of how closely clustered repeated shots are (or might be). That "margin of error" means that repeated polls under identical conditions (same questions, same questioners, etc.) but on different samples taken randomly from the same population, 95% of the repeated polls will likely fall within ±3%-points of the grand mean of all possible polls. Quite obviously, one may have a tight cluster of shots, all of which are high and to the left (as in the lower left of the drawing). That is, a precise estimate that is biased.
IN STATISTICS, bias retains its original meaning of being simply "slant, or oblique" in this case from the unknown (and often unknowable) true value, as the shot cluster in the lower left panel is "oblique" from the bull's eye. It no more implies deliberate nefariousness or cheating than the statistical term error implies a mistake or blunder. The only way to assess bias is from a True Value (aka Reference Value). For example, a gage block or other working standard traceable to master standards kept at NIST. In the case of a political poll, we can take the actual election as the True Value, though we must keep in mind Dewey v. Truman: the sentiments of the electorate may have shifted over the time since the poll was taken and the election was held.*
(*This is very different from Landon v. Roosevelt, which was a case of bias induced by the sampling method used by the Literary Digest.)
BUT THERE IS ANOTHER PITFALL to be wary of when hearing of precision. Precision of what?
In a recent exchange of messages on the topic of
 INDEED. Let's see how that works. We will take a very simple model: estimating the density of coal in a bunker by measuring the radiation backscatter of the coal. Since different veins of coal may differ in their radioactivity, the relationship of the surrogate measure (backscatter) to the desired measure (density) must be calibrated for each mine from which shipments come. This is done by taking a known amount (weight) of coal from the coal pile following ASTM methods and packing it into a calibration tube to various volumes, hence to various densities. Since on the sample, both the density and the backscatter will be known, a relationship can be determined by the usual linear regression methods. (The range of likely densities is such that non-linear effects should not appear.) The technician may then proceed to the bunker and obtain backscatter readings from this great big honking pile of coal and, using the surrogate and the calibration curve, predict the density of the coal in the bunker.
INDEED. Let's see how that works. We will take a very simple model: estimating the density of coal in a bunker by measuring the radiation backscatter of the coal. Since different veins of coal may differ in their radioactivity, the relationship of the surrogate measure (backscatter) to the desired measure (density) must be calibrated for each mine from which shipments come. This is done by taking a known amount (weight) of coal from the coal pile following ASTM methods and packing it into a calibration tube to various volumes, hence to various densities. Since on the sample, both the density and the backscatter will be known, a relationship can be determined by the usual linear regression methods. (The range of likely densities is such that non-linear effects should not appear.) The technician may then proceed to the bunker and obtain backscatter readings from this great big honking pile of coal and, using the surrogate and the calibration curve, predict the density of the coal in the bunker. What we see here is the scatter diagram with the fitted model. (Now you know why I'm using a model with one X and one Y.)

You will notice that the model has an R^2 of 91.6%. This means that 91.6% of the variation in backscatter is explained by the relationship to coal density. That's pretty good. The relationship is Y=9946-59.17X. Since this implies a backscatter of 9946 when the coal has density 0, we realize that there may be boundary effects, regime changes, or the like. But so long as we are far from the boundaries, this will do, fapp.
But all estimates are estimates. That is, they all come with wiggle. The mean of a sample has a standard error of SE = σ/√n, for example. Hence, the two parameters of the model, the slope and the intercept, are also subject to sampling variation. Fortunately, these can be estimated:

The red dashed lines show the confidence interval within which repeated regression lines may fall 95% of the time, were the sampling done repeatedly. Imagine the regression line moving up and down (change of intercept) or rotating like a propeller (change of slope) within the boundaries of the dotted lines. (Notice also that the confidence interval is wider for the extreme values than for the central values.) If the coal density were 68, the regression line tells us to expect a backscatter of 5922. Well and good. But this is an expected value; that is, a mean. The confidence interval tells us that this estimate is good to a precision of ±60. That is, the "true mean" (assuming no bias) lies between 5862 and 5982.
BUT THIS IS A BOUND ON THE ESTIMATE OF THE MEAN, A PARAMETER. It does not tell us the limits on the actual backscatter readings we may expect, as you can see in the next graph:

Actual backscatters spread out beyond the confidence limits, because those are limits on the mean value of Y at each X. To understand the variation of the actual data, we need the prediction limits:

These are the outer, light blue dotted lines on the chart. We would expect 95% of the data to fall within these limits by random chance. That is, 5% of the data may fall outside the limits for "no particular reason." Data may also fall outside the limits due to assignable causes; that is "for a particular reason." (Regular readers of this blog will recollect that there is no point hunting for the specific cause of a random fluctuation, even if the random fluctuation is undesirable. This is because there is no particular cause for a random fluctuation; rather, there are many causes.)

Here we see the distinction between the confidence interval and the prediction interval. If the coal density were really 68, the expected value of the backscatter would be somewhere between 5862 and 5982, or ±60; but the actual measured value the technician gets with his ray gun will fall between 5712 and 6132, that is, ±210.
AND NOW YOU SEE THE GREAT TRAP. Confidence bands are always narrower than prediction bands. The scientist may emphasize the precision of the parameter estimate and the media reporter may hear what he thinks is a high precision for the model for the forecasted values of Y. Dishonest scientists may do this deliberately to pretend to a greater precision than they have achieved. And to be charitable, the scientist may be more savvy in physics (vel al.) than in statistics. We know this is true of social "scientists."




Thank you for this excellent post. The social “sciences” are indeed confused, and recovering a clear understanding of the term “accuracy” would go a long way toward clearing up much of the chaos. I recently read a paper in which multiple judges rated the narcissism of persons in photographs. The averages of these ratings were then correlated with the self-reported ratings of narcissism provided by the photographed persons. The resulting Pearson’s correlation was a whopping .25, printed with the magical asterisk indicating statistical significance (nay, two asterisks for doubly important results). Indeed, the correlation was described as indicating “remarkable accuracy” of snap judgments…and such methods and interpretations are considered the gold standard in psychology.
ReplyDeleteI fear the social “sciences” may never rise above the “damned lies” level of statistical analysis. Too many generations have been indoctrinated into a thoughtless set of rituals that very few truly understand. Sadly, I have spent much of my career contributing to the mess. Exercising the virtue of hope, however, I have attempted to at least recover some Aristotelian common sense and a clearer understanding of accuracy here: http://psychology.okstate.edu/faculty/jgrice/personalitylab/methods.htm#OOM
JWG-
ReplyDeleteso, 6% of the folks that "looked" narcissistic self identified as narcissistic? Is that right?
If so, I see why folks love using the "r=#" setup....
Hi Foxfier,
DeleteI see you have squared the correlation coefficient. This value can be interpreted as indicating the proportion of shared variance between the two variables, but it alas cannot be interpreted as an index of accuracy. In other words, it is not likely the case that 6% of the folks who looked narcissistic also self-identified as such. We need the raw data and a different type of analysis to assess accuracy. In this regard, and for this example, matters are made worse by the researchers’ use of different questionnaires to “measure” narcissism for the raters and for those in the photographs. Why did they do so? They did not say, and I cannot guess, but their choice complicates the matter of attempting to map one set of ratings onto another to determine accuracy.
The use of different scales does, however, fit with psychologists’ generic, untested assumption they are working with attributes that are structured continuously and can be measured accordingly. The belief is that using two different “measures” of narcissism is like a child using two different rulers (one scaled in inches and one in centimeters) to measure the length of a pencil – both rulers work just fine and the choice between the two is arbitrary. The problem for psychologists is that they have not done the difficult scientific work to demonstrate the continuous, quantitative nature of their most cherished attributes, including intelligence, extraversion, depression, anxiety, etc. To continue the analogy, then, the narcissism researchers don’t even have one good ruler, let alone two rulers with values that can be transformed from one scale to the other. The application of parametric statistics to psychological data has been rightly criticized since the early 1900s, which leads us to conclude that the Pearson’s correlation coefficient is itself dubious. In the end, though, collecting numbers and cranking them through some statistical machine “pays the bills,” and so the rituals continue unabated.