 |
| Ruminations |
In partes priores, we learned that as science proceeded from matters of organized simplicity (a few elements connected one to another) to disorganized complexity (many elements acting randomly) to organized complexity (many elements organized into patterns), the scientific approach progressed from mathematics (e.g., Boyle's Law) to statistics (e.g., thermodynamics) to models (e.g., general climate models). As it did our understanding of the phenomena decreased. It is easy to understand:

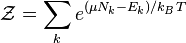
if a model is producing shortwave surface radiation fluxes that are substantially biased relative to observations, it is impossible to determine whether the error arises from the radiative transfer model, incoming solar radiation at the top of the atmosphere, concentrations of the gases that absorb shortwave radiation, physical and chemical properties of the aerosols in the model, morphological and microphysical properties of the clouds, convective parametrization that influences the distribution of water vapor and clouds, and/or characterization of surface reflectivity.
-- Judy Curry, "Climate Science and the Uncertainty Monster"
Previously, TOF discussed various aspects of uncertainty: viz.,
- the kind of incertainty,
- the degree of uncertainty, and
- the location of uncertainty within the model.
Kind
|
Degree
|
Location
|
Epistemological
Ontological
|
Determinate
Statistical
Scenario
Recognized Ignorance
Total Ignorance
|
Context
Model Structure
Model Execution
Inputs
Parameters
Outputs
|
| Two lips |
A Tiptoe Through the Tulips
Now let's take a look at some typical uncertainties in models, starting at the planning end and proceeding to the calibration. In illustration, we'll use a simple linear model just for slaps and giggles. In the slide below, the Y-values are the performances that we are trying to model, say Performance, Cost, and Reliability of an airframe or some such thing. The X-values are the inputs and internal variables, such as properties of materials, dimensions, clearances, and the like. The idea is that if you- plug in actual values of X and
- calculate the model outputs Ŷ,
- those outputs ought to be "close" to the actual performances, Y.

Calibration data are data for which both Y and X are known. By plugging both into the model, we can solve for the parameters b that make the model work by jiggering the b-values until (Y-Ŷ)² has been minimized.
The assumption is that when we plug in new Xs, the resulting Ŷ-values -- the model outputs -- will also be good predictions of those unknown Ys. Difficulties arise when the new Xs lie outside the boundaries of the original data.
Example 1: Suppose some psychologist did some testing with an instrument* used to measure (say) "attractiveness to males" and then performed regression on a gazillion possible factors such as "licking her lips"** to identify the important factors influencing attractiveness-to-males, and obtained b-values for the regression model. But if all of the test subjects were WEIRD people*** can the psychologist really make predictions about what non-WEIRD people find attractive?
Attractive to Ubangis.
Yes, that's a solar panel in her lip piercing.

(*) instrument. Actually, a questionnaire; but social scientists call them "instruments." Aren't they just so cute when they play science dress-up?
(**) licking her lips. No, TOF is not making this up. Someone has to pay for the grants and it may as well be the taxpayers.
(**) WEIRD. Western, Educated, Industrialized, Rich, and Democratic.They comprise 95% of all respondents in academic psychology papers.
 |
| Attractive to Choctaws, Lanena Grace John (right) 2013/14 Choctaw Princess |
Example 2: Suppose a climatologist measures tree ring growth on a stand of bristlecone pines in Patagonia and, for the thermometer era, finds a good linear correlation with measured temperatures in that region. But ring growth is also sensitive to many other causal factors, including rainfall, drainage, and whether a deer took a dump on its nearby roots. So does the correlation found in the calibration data holds for other trees in other locations in other years when these other factors may have been different?To put it another way, an empirical correlation Temp=b0+b1Ring does not have the same sort of ontological standing as a causal equation like F=ma or E=mc². It looks like an equation from traditional science, but it's not the same kind of thing. You can't look at organized complexity with the same mindset as at organized simplicity, or even at disorganized complexity.
The First Uncertainty: What X's Should We Include?
Much depends on the context of the problem the model is intended to resolve. When Napoleon asked Laplace where in his "System of the World" God appeared, the mathematician famously replied, "Sire, I have no need of that hypothesis." Similarly, Sean Carroll wrote that if the soul existed, it would have to have a term in Dirac's equation. But "it doesn’t and we can’t imagine what it would mean for it to have one." Rather than conclude that the equations must be incomplete, many suppose that this means the objects do not exist.But the parsimony of models -- see William of Ockham for details -- requires that factors be excluded if they're not needed to estimate Y "close enough" for practical purposes. The speed of light does not appear in Newton's model because it served no purpose in what he was trying to accomplish. Similarly, Darwinian evolution does not appear in the manuals used by auto mechanics rebuilding a transmission.
Equally vexing is neglecting factors that ought to have been included. Climate models famously excluded solar effects and clouds, largely because no one initially knew how to account for them. It now appears that they play more important roles in the game than previously supposed.
 In engineering, a Quality Function Deployment matrix is often useful for for identifying key X factors, as long as we remember that the matrix is a repository for our knowledge and not a replacement for it. Too many QFD matrices are hastily done or blown off with too little thought.
In engineering, a Quality Function Deployment matrix is often useful for for identifying key X factors, as long as we remember that the matrix is a repository for our knowledge and not a replacement for it. Too many QFD matrices are hastily done or blown off with too little thought.The example shown, for a pocket calculator, seeks to model the performance "Easy to Read" as a function of five factors, with the matrix entries indicating the weight or importance of each factor on the performance. Four other factors are thought to have some lesser impact on the performance metric.
Note: "Mat'l cost" really has no direct impact on Y=Easy to read. It is a design constraint, not a design input, and so is somewhat misplaced in the analysis.Each row in the matrix is a different Y. Each column is a different X. Each Y depends upon multiple Xs; and the same X may loads onto multiple Ys. This is what makes it so hard to design a fully satisfactory product. The values of X that optimize one Y may sub-optimize other Ys.

Another way of identifying important Xs is the Parameter Diagram (P-diagram), which breaks the Xs up into Signals, Design Parameters, and Noise; and Performances into Outputs and Waste or Side Effects or Error States.
Don't take the little bell curves seriously. They indicate only that each of X (and Y) is variable, and that these variations combine in the model. Researchers often overlook this and focus instead on the precision of the estimates of the parameters of the model. More on this "propagation of variances" later.
Example: In "The Predictability of Coups d'Etat: A Model with African Data," Robert W. Jackman developed a set of four Xs by which to estimate the coup-proneness of Sub-Saharan African states:
Y: Coup index. The weighted sum of successful coups (5), unsuccessful coups (3), and plots (1).The selection of which variables to include in the model is a potent source of uncertainty. Has a key variable been omitted? A useless variable included? In his paper, Jackman gives sound reasons based on prior research for the conceptual variables that he is attempting to operationalize. IOW, he did not simply pop them out of thin air. Two of them have been made binary for heuristic reasons. That is, they seemed to work better that way. But M as defined defies reality. What is the basis for adding those two percentages? What does the resulting sum mean?
M: Social mobilization. The percentage of the labor force in nonagricultural occupations (c.1966) plus the percentage of the population that is literate (c.1965).
C: Ethnic pluralism. The percentage of the population belonging to the largest ethnic group, treated as a binary variable: either greater than 44% or not.
D: Party dominance. The percentage of the vote going to the winning party in the election closest but prior to independence.
P: Political participation. The percentage of the population voting in the aforesaid pre-independence election, treated as a binary variable, either greater than 20% or not.
The Second Uncertainty: A Close Shave with Billy Ocks.
There are many more ways to be wrong in a 10^6 dimensional space than there are ways to be right.—Leonard Smith |
| Why does Ockham get all the credit for the well-known Principle of Parsimony? Why do Moderns think it is a scientificalistic fact? |
Digression: What's the probability that You know some A who knows B who knows Buzz Aldrin?
You→"A" (+1)→"B" (+2)→Buzz (+3)
"Unlikely," most people have said in TOF's training classes -- in which he was trying to make a point about estimating likelihoods for failure modes and effects analysis (FMEA). But as it turns out, TOF knows SF writer John Barnes and John Barnes knows Buzz Aldrin. So if you know TOF, you are separated from Buzz by no more than three degrees of separation.
That's because you know easily 1000 people -- family, neighbors, school-chums, co-workers, acquaintances, etc. -- and each of them knows 1000 people. And each of them knows 1000 people, which makes a billion people out at step 3. So even allowing for overlap and duplication it's almost dead certain that you know someone who knows someone who knows American X, no matter who X is.TOF has collected examples over the years. You know TOF (sorta) (+1) and TOF knows:
- a friend of the Incomparable (+2) who went to high school with Robert Redford (+3).
- a client named Norayr (+2), who knew the Armenian Patriarch of Jerusalem (+3).
- Jerry Pournelle (+2), who knew Ronald Reagan (+3) and knows Newt Gingrich (+3).
- Ed Schrock (+2), who knew W. Edwards Deming (+3) -- who knew Buffalo Bill Cody (+4!).
- Rep. Tim Wirth (+2) and Sen. Gary Hart (+2), who know inter alia then-Arkansas governor Bill Clinton (+3)
- a nuclear inspector in Vienna (+2) who knew Nelson Mandela (+3)
IOW, probabilities are often different than you think.
 |
| Unabomber before he was Unabomber |
Now, TOF told you that to tell you this.
Kaczynski told his class, my friend told me: "With seven variables you can model any set of data -- as long as you can play with the coefficients." There will be no "unexplained" variation left over to warrant an eighth factor. That's why big models always seem to fit so well and have large R² values, and the modelers "don't need" the eighth factor.
Except that if you drop one of the other seven and replace it with number eight, you can get another good fit (with different b-coefficients). Many moons ago, TOF read an article in Scientific American, the title and author of the article now escape the keen steel trap of his mind, in which an R² value was improved by adding a variable that was completely irrelevant to the model! MLB batting averages, as he recalls.
So you can screw up your model by having too many terms in it. It will look better than it is because by fiddling with the bs you can get a good-looking R².
The Third Uncertainty: The Curse of Multicollinearity

Example: Thickness of a Molded Plastic Part was correlated against a laundry list of potentially important factors involving the material and the molding machine:
- Film Density
- Tensile Strength
- Air Bubbles
- PreHeat Temp.
- Plug Temp.
- Air Pressure
- Vacuum Pressure
- Mold Temp.
- Dwell Time
which returned an R² = 86%.Thickness = 12.7+0.254 FilmDens+0.00008 Tensile-0.00517 Airbubbles
-0.0421 PreHeat-0.00610 PlugTemp-0.0106 AirPres
-0.0282 VacPress+0.00419 MoldTemp-0.0310 DwelTime
However, it turned out that Film Density and Tensile Strength were positively correlated and that Air Pressure and Vacuum Pressure were negatively correlated, meaning that including both of each pair of factors added no information to the model. After consideration of possible physical causations, the decision was made to drop Tensile and AirPres, yielding a reduced equation:
which had an R² = 86%. That is, dropping two variables had no impact on explanatory power. Note too that the coefficients of the factors have changed. It's a different equation, a different model. If Napoleon or Sean Carroll asked, "Where is Air Pressure in this system?" we would answer, "Sire, we had no need of that hyposthesis!"Thickness = 13.2+0.258 FilmDens-0.00469 Airbubbles-0.0430 PreHeat
-0.00635 PlugTemp-0.0182 VacPress+0.00373 MoldTemp
-0.0232 DwelTime
We will look at the related problem of serial correlation in Part V.
The Fourth Uncertainty: Conjuring Factors from the Vasty Deep
Glendower: I can call spirits from the vasty deep!Hotspur: Why, so can I, or so can any man. But will they come when you do call for them?
-- Shakespeare, Henry IV Part 1: Act 3, Scene 1

The penalty is that the new "hidden" factors do not correspond to any factor in the real world. In the graph, X1 is Yield Strength and X2 is Tensile Strength. But Z1 and Z2 correspond to combinations of little bits of both. If that makes any sense. A model based on these Zs may have good predictability, but it is no longer clear what the model means. This is a particular trouble with Big Data, which often leads to models of surpassing opaqueness.
Weinberger tells of a computer program called Eureqa that seines the ocean of data and iteratively constructs equations which adequately predict the outputs. This sounds like orthogonal factor analysis by way of step-wise regression - on steroids. But the resulting equations will be heuristic and not built on any insight into the problem. "After chewing over the brickyard of data that Suel had given it, Eureqa came out with two equations that expressed constants within the cell. Suel had his answer. He just doesn't understand it and doesn't think any person could." But that is probably because the various Xs in such equations need not correspond to any physical factor in the system.This is exactly what Billy Ockham warned us against: don't have too many terms in your model, or you won't understand your model. It gets worse when you don't even understand the terms. For discussion relating to global temperature, see "Step 3" here.
Summulae
The first group of uncertainties (once we have gotten past correctly assessing the context in which the model will be applied) deal with the identification of the predictors (Xs) in the model. Like Little Bear's porridge these should be neither too many nor too few.- Selection of the wrong Xs; non-selection of pertinent Xs. The kneebone's connected to the thighbone, and the thighbone's connected to the hip bone. The skeleton won't dance unless all the bones are in place.
- Too many Xs leads to overfitting and the modeling of random noise instead of signal. A model that includes everything including the kitchen sink is likely to give results much like one finds in the trap of a kitchen sink.
- Mutually correlated Xs lead to overfitting and to unreliable coefficients. You actually have one factor masquerading as two and will believe yourself less uncertain than you really should be.
- Principle components analysis uncorrelates multicollinearity, but produces "factors" that do not correspond to physical reality. An excessive fascination with the mechanics of modelling may lead you to forget the reality you were trying to model in the first place.
Suggested Reading
- Box, George E.P., William G. Hunter, J. Stuart Hunter. Statistics for Experimenters, Pt.IV “Building Models and Using Them.” (John Wiley and Sons, 1978)
- Carroll, Sean. "Physics and the Immortality of the Soul," Scientific American guest blog (May 23, 2011)
- Curry, Judith and Peter Webster. “Climate Science and the Uncertainty Monster” Bull. Am. Met. Soc., V. 92, Issue 12 (December 2011)
- El-Haik, Basem and Kai Yang. "The components of complexity in engineering design," IIE Transactions (1999) 31, 925-934
- Hamblin, Robert L., R. Brooke Jacobsen, Jerry L.L. Miller. A Mathematical Theory of Social Change, (John Wiley and Sons, 1973). [link is to a journal article preceding the book]
- von Hayek, Friedrich August. "The Pretence of Knowledge," Lecture to the memory of Alfred Nobel, December 11, 1974
- Jackman, Robert W., "The Predictability of Coups d'Etat: A Model with African Data." (Am.Pol.Sci.Rev. (72) 4, (Dec. 1978)
- Kuttler, Prof. Dr. Christina. "Reaction-Diffusion equations with applications." Technische Universität München, Lehrstuhl für Mathematische Modellierung, Sommersemester 2011
- Petersen, Arthur Caesar. "Simulating Nature" (dissertation, Vrije Universiteit, 2006)
- Pielou, E.C. An Introduction to Mathematical Ecology, (Wiley-Interscience, 1969)
- Rashevsky, N. Looking at History Through Mathematics, (MIT Press, 1968)
- Ravetz, Jerome R. NUSAP - The Management of Uncertainty and Quality in Quantitative Information
- Renfrew, Colin and Kenneth Cooke (eds.) Transformations: Mathematical Approaches to Culture Change, (Academic Press, 1979)
- Rodionov, Sergei N. "The Problem of Red Noise in Climate Regime Shift Detection"
- Rosen, Robert. "Morphogenesis in Biological and Social Systems," in Transformations: Mathematical Approaches to Culture Change., pp. 91-111. Academic Press, 1979
- Steirou, E. and D. Koutsoyiannis. "Investigation of methods for hydroclimatic data homogenization," European Geosciences Union General Assembly, Vienna 2012
- Swanson, Kyle L. "Emerging selection bias in large-scale climate change simulations," Geophysical Research Letters
- Turney, Jon. "A model world." aeon magazine (16 December 2013)
- Walker, W.E., et al. "Defining Uncertainty: A Conceptual Basis for Uncertainty Management in Model-Based Decision Support." Integrated Assessment (2003), Vol. 4, No. 1, pp. 5–17
- Weaver, Warren. "Science and Complexity," American Scientist, 36:536 (1948)
- Weinberger, David. "To Know, but Not Understand," The Atlantic (3 Jan 2012)
- E. C. Zeeman, E.C. "A geometrical model of ideologies," in Transformations: mathematical approaches to culture change, pp. 463-479, Academic Press, 1979




{kind=link}
{kind=link}
I suspect that the Scientific American article you can't remember is http://www.scientificamerican.com/article/steins-paradox-in-statistics/
ReplyDeletewhich made a pretty strong impression on me when I read it and I kept looking for a place where I could USE it.
On a separate subject, I have had an idea for a HS-level science project which I think could provide naked-eye evidence for a non-geocentric solar system. The idea seems so simple that I am SURE someone has thought of this before-- yet I can't find any sources. May I bother you for your opinion on this? Thanks in advance, Pete Peterson
You might be right. It sounds familiar. I kept thinking "Simpson's Paradox," but I knew that wasn't right.
Delete+++
I'm not a HS science teacher, but feel free to explain your experiment. Does it involve stellar aberration, parallax, or Coriolis?
I was watching Jupiter setting behind our barn, (at least 200 feet away) which has a pretty sharp roof, and saw it take what seemed a few seconds to disappear from the time it seemed to start getting dimmer to the time it disappeared altogether. A few minutes later, watched a nearby star set and wink out instantaneously. I backed up so I could see Jupiter again and this time counted, it took about 4 seconds to disappear. I backed up again and and again and got around 4 seconds each time (no stopwatch, "timed" it by singing the fastest fiddle tune I know repeatedly, which is about 5 notes per second). Did the arithmetic: if the earth turns (or the stars turn) 15 degrees per hour, then my four seconds corresponds to an angular diameter of about 1 minute of arc. A few nights ago I looked at Mars, nearly at opposition, and it took about 1.4 seconds (seven notes of "Soldiers Joy") to disappear behind a vertical straightedge I had rigged up. That's what I have DONE; what I BELIEVE is that if a patient observer were to follow (say at 2 week intervals) the apparent angular diameter of visible planets would change with time, and be largest when that planet is brightest-- Venus and Mars would change greatly, while Jupiter would barely change and Saturn barely if at all. It's very hard not to jump ahead to "what we all know" but I think this could be strong evidence against a geocentric universe. Which makes me wonder-- if Tycho had his huge equipment, didn't he notice angular diameter? I haven't seen anything suggesting that he had! (Note that even by 1616 we didn't have reliable ways of measuring seconds of time, which is why I did it by singing tunes to myself. I may not be accurate, but think I am reasonably consistent with timing-- and I am not unmindful of information that Galileo's father was a lute player) Again, thanks in advance!
DeleteThat’s a pretty good measurement given the instruments used, Mr. Peterson. I just looked it up: the maximum angular diameter of Jupiter as viewed from Earth is a hair over 50 seconds of arc. (The minimum is about 30, so it does change more than you suggest.)
DeleteI suppose part of the reason that naked-eye astronomers didn’t make such measurements is that they never thought of the planets as having appreciable angular diameters. Another part would probably be that observatories were deliberately constructed in such a way as to give the widest possible unobstructed view, without any handy barns and things to take such measurements from.
Actually, they did measure the angular diameter. It was the reason they thought the stars, including the planets, were so much closer than they are. So close, in fact, that parallax should have been visible if the earth went round the sun. But the diameters are inflated by atmospheric aberration (which they knew about but discounted when the star was higher in the sky) and the Airy disks (which they did not know about, and which even telescopes did not eliminate). IOW, these diameters are to some extent optical illusions.
DeleteDid they all think the planets and stars were much closer? What about the Almagest saying the distances to the stars should just be treated as infinite and the Earth as an infinitesimal point of no dimensions? (Or was it that even the smaller-than-actual distances they estimated were so much bigger than their "only off by 1.6%-16.3% depending whose 'stadium' unit Eratosthenes was using" estimate of the size of the Earth, that the Earth could be treated as a point?)
DeleteI just learned about Airy disks; from the Wikipedia article it looks like the resolving power of the human eye is about 20 arc-seconds. But I can still remember the star going out abruptly (between one note and the next) while Jupiter took about four seconds. . . as Feynman said "the first rule is that you must not try to fool anyone, and the easiest person to fool is yourself". Thanks.
DeleteSophie, the estimated distance to the inner surface of the shell of the fixed stars was estimated at an unimaginable 73 million miles (equiv.) For practical purposes in those days, that might as well be infinite wrt the diameter of the earth.
DeleteThere being No Coincidences, we have also the recent posting
ReplyDeletewattsupwiththat.com/2014/04/30/nobody-expects-the-climate-inquisition/
okay, the bit about women licking their lips being thought more attractive/available made me laugh because I was firmly taught at early adolescence (early 80s) to never lick my lips in public, most especially when some man might be watching, because it indicated a willingness to perform fellatio. No, I'm not making this up. My reaction as a 12 yr. old girl was, "you've got to be joking."
ReplyDeleteI nominate for the reading list Vapnik, _The Nature of Statistical Learning Theory_, a book that I found particularly useful for systematically understanding inference and overfitting. It's not for the faint of heart, but neither is it ridiculously hard as technical books go, and it's concise enough that it's a physically small book that still explains how to implement computer software which learns to recognize handwritten digits by training itself from a body of examples. It's also structured in such a way that one can learn a lot by semi-skimming it without actually grinding through all the details: unlike some math-heavy technical books, it has quite a lot of framing text summarizing, explaining motivation and tradeoffs, and illustrating with examples what it's doing. I also have a particular interest in reading work by people who were involved in working out some of the details (this is the Vapnik of "Vapnik-Chernovenkis dimension") and in this case that helps me smile instead of groaning when a plus-size ego seems to be on display: correspondingly plus-size accomplishment is a mitigating factor.
ReplyDeleteWorth mentioning also is Mackay's _Information Theory, Inference, and Learning Algorithms_ which only touches on overfitting instead of targeting it and making the rubble bounce the way Vapnik does, but which seems to be a pretty good more general book with the special virtue of being downloadable for free.
Dear Michael Flynn:
ReplyDeleteThis doesn't relate directly to the subject under discussion here, but it IS a query regarding a recent survey and the conclusions reached as a result of the data gathered in that study:
While reading io9 (which I enjoy a lot), I came across this article: (http://io9.com/are-religious-beliefs-going-to-screw-up-first-contact-1574043211?utm_campaign=socialflow_io9_facebook&utm_source=io9_facebook&utm_medium=socialflow)
The title: “Are Religious Beliefs Going To Screw Up First Contact?”
Based on: “...[clinical neuropsychologist Gabriel G. de la Torre]…sent a questionnaire to 116 American, Italian, and Spanish university students.”
Reached this conclusion: “…he found that many of the students — and by virtue the rest of society — lack awareness on many astronomical aspects. He also learned that the majority of people assess these subjects according to their religious beliefs.”
As a statistician, what do you make of the significance of the conclusion of this survey?
...What makes a neuropsychologist think he's qualified to assess anyone's knowledge of any science, except neuropsychology? (Leaving to one side whether that's not just a sexier name for "neo-phrenology".) Aside from the fact many scientists are absolute laymen outside their specialty (meaning he's not only unlikely to know what ideas are important, in astronomy, but also how to ask intelligent questions about those important ideas), constructing a questionnaire in such a way that its results are actually meaningful, is a specialized skill in and of itself—one neuropsychologists are not ordinarily trained in.
DeleteEven taking his study at face value, shouldn't the actual headline be "science education is so laughably bad that even in college, people rely on other fields of inquiry to judge questions of astronomy"? That doesn't actually seem to be something those other fields of inquiry have to answer for.
Finally, io9 needs to fire its editor. Like, in a kiln, or out of a cannon—that article's errors might've been perfectly calculated to sound like a pseudo-intellectual who doesn't actually understand the nuances of the highfalutin phrases they use. "By virtue" is simply misused (at the very least it would be "by virtue of [something]"); it really ought to be "by extension" or "by extrapolation". It should also be "aspects of astronomy" not "astronomical aspects"—those are not interchangeable ("astronomical aspects" are aspects of something else that are related to astronomy, e.g. "astronomical aspects of calendar-making").
This comment has been removed by the author.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDelete